To meet all the requirements our clients may have including fast turn around times we challenged our engineering team to focus their efforts on creating a major speed improvement.
In this blog we talk about steps we took to speed up one of the major time consuming processes we have. We were able to turn it to a X-time improvement (X for the number of cores); code as fast as the computer can handle.
Our task was to optimize the speed of the cleaning and ETL code to finish running more data points in a shorter time period. We had some general tasks to try which we thought would have a good effect on the code’s efficiency:
- Cythonize the code
- Release the GIL to use multithreading
However because of problems releasing the GIL (namely working with custom and python objects) multithreading did not work out. We then took the path of multiprocessing instead.
1. Cythonizing The Code
Intro
You may have known that compiled languages like C, C++ are much faster than interpreted ones like Python - rather than having the interpreter run through the code line by line, the entire code is built into machine code for the processor to execute.
C++ is a static language and variables are only allowed to have one type throughout its lifetime. Every time the variable is being used there’s no need to guess or check what type the variable is at the cost of flexibility in code, this gives much greater efficiency.
This brings us to Cython. Cython is a language released in 2007 meant to be a bridge between Python’s ease of use and C++’s speed and efficiency. By allowing the code to be written in both Python and C++’s syntax when needed we are able to make the most inefficient parts of the code very efficient.
What We Did
We started by looking through our code and finding places where we can typeset variables that were being used often. It’s important to note that we had to specify the language at the top of the file in order for it to compile without errors.
Some changes:
- Change Python variables into C’s type-set variables
- Use cdef functions instead of def
For example:
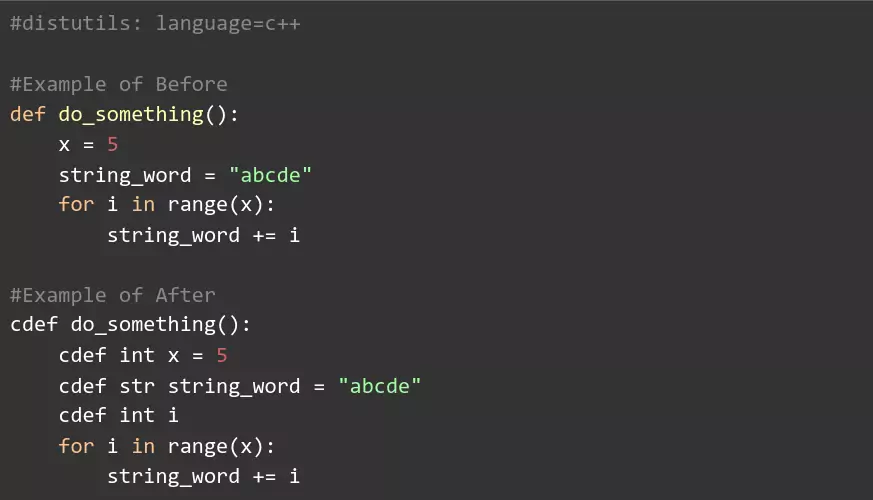
With these changes, the Python interpreter no longer has to guess the type of each variable it comes across, resulting in speed improvements of up to 200%. Unfortunately, cythonizing the entire project gave us some problems with some of the data:
- We were using sub libraries (like regex) that we didn’t want to convert to Cython because they were not nogil safe.
We moved our functions into a separate file which we cythonized. This type of changes resulted in moderate speed improvements of about 30% which worked with all the data.
2. Time For Multi-Processing
Since multi-threading had failed, we had to change our approach and try multi-processing. We had issues pickling custom objects at first, but now that our main code is in its own file, we could attempt it again.
Pickling is part of multi-processing: serialization, converting objects into a series of bits, in order to share objects without losing information. However, pickle can’t be used on custom objects and dill (a more robust version of pickle) is inconsistent.
There are a few libraries for multiprocessing, one of which is multiprocessing:
pip install multiprocessing
With this library we can instantiate objects like Pool() and Process(), and; without going into detail about the difference between Pool and Process, allows us to begin running things in parallel.
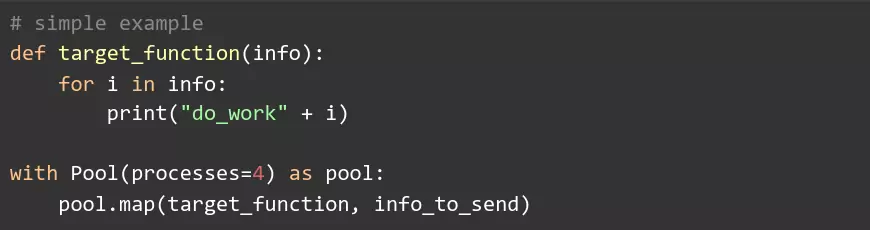
After implementing multiprocessing, there were indeed very noticeable speed increases - around 200% faster than the original code when using 2 processes.
Conclusion
It was evident that using Cython for portions of code which were run repeatedly gave us great performance boosts and combining this with multiprocessing made an incredible difference. The GIL is tricky to work with and as a result multi-threading was not a viable option for us (at this point at least).
Next Steps: More Memory Efficiency!

